本篇内容介绍了“Linux下Tomcat怎么开启查看GC日志和调优”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
创新互联建站于2013年成立,是专业互联网技术服务公司,拥有项目成都网站建设、网站制作网站策划,项目实施与项目整合能力。我们以让每一个梦想脱颖而出为使命,1280元延安做网站,已为上家服务,为延安各地企业和个人服务,联系电话:189808205751、在Tomcat 的安装路径下,找到bin/catalina.sh 加上下面的配置,具体参数,自己配置:
[root@CentOS7 tomcat]# vim bin/catalina.sh
JAVA_OPTS='-Xms1024m -Xmx2048m -XX:PermSize=64M -XX:MaxNewSize=128m -XX:MaxPermSize=64m -XX:ParallelGCThreads=8 -XX:+UseConcMarkSweepGC -Xloggc:/usr/local/tomcat/logs/tomcat_gc.log'1
2、重启tomcat
[root@centos7 ~]# systemctl restart tomcat1
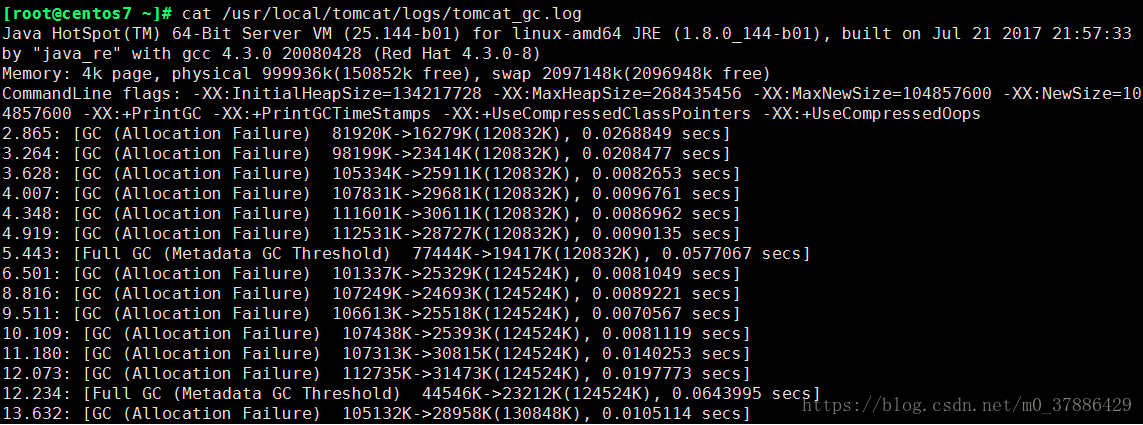
3、查看GC日志
[root@centos7 ~]# cat /usr/local/tomcat/logs/tomcat_gc.log1
1、windows 安装java 环境
(1) 官网下载JDK
官网地址
下载,必须点击同意协议
(2)安装JDK1.8版本
设置自己的安装路径,取消公共JRE
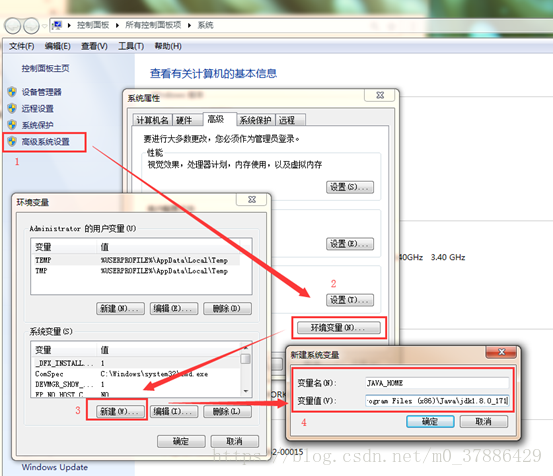
(3)设置3个环境变量
① 找到自己安装jdk的bin路径,我的安装路径是 C:\Program Files (x86)\Java\jdk1.8.0_181
② 在高级系统设置—>环境变量—>新建
新建2个环境变量JAVA_HOME、CLASSPATH:
修改一个变量:Path
(4)安装完毕,测试
在cmd中输入 java、javac、java -version三个命令会有不同的效果
2、运行gchisto,分析gc日志
(1)运行gchisto
解包后,打开cmd命令行,执行下边的命令,注意:自己解包后gchisto的路径
java -jar D:\gchisto-master\release\GCHisto-java8.jar
(2)打开后效果
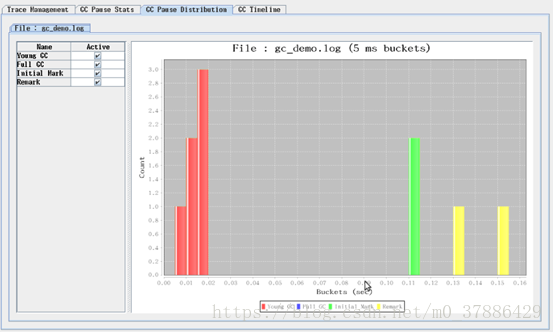
(3)分析Tomcat 的gc 日志
将linux 下的tomcat 日志 导入到windows 上的gchisto中,查看效果
1、堆大小设置
① -Xmx3550m -Xms3550m -Xmn2g -Xss128k
-Xmx3550m:设置JVM大可用内存为3550M。
-Xms3550m:设置JVM初始内存为3550m。此值可以设置与-Xmx相同,以避免每次垃圾回收完成后JVM重新分配内存。
-Xmn2g:设置年轻代大小为2G。整个堆大小=年轻代大小 + 年老代大小 + 持久代大小。持久代一般固定大小为64m,所以增大年轻代后,将会减小年老代大小。此值对系统性能影响较大,Sun官方推荐配置为整个堆的3/8。
-Xss128k: 设置每个线程的堆栈大小。JDK5.0以后每个线程堆栈大小为1M,以前每个线程堆栈大小为256K。更具应用的线程所需内存大小进行调整。在相同物理内存下,减小这个值能生成更多的线程。但是操作系统对一个进程内的线程数还是有限制的,不能无限生成,经验值在3000~5000左右。
② -XX:NewRatio=4 -XX:SurvivorRatio=4 -XX:MaxPermSize=16m -XX:MaxTenuringThreshold=0
-XX:NewRatio=4:设置年轻代(包括Eden和两个Survivor区)与年老代的比值(除去持久代)。设置为4,则年轻代与年老代所占比值为1:4,年轻代占整个堆栈的1/5
-XX:SurvivorRatio=4:设置年轻代中Eden区与Survivor区的大小比值。设置为4,则两个Survivor区与一个Eden区的比值为2:4,一个Survivor区占整个年轻代的1/6
-XX:PermSize:设置永久代(perm gen)初始值。默认值为物理内存的1/64。
-XX:MaxPermSize:设置持久代大值。物理内存的1/4。
-XX:MaxTenuringThreshold=0:设置垃圾大年龄。如果设置为0的话,则年轻代对象不经过Survivor区,直接进入年老代。对于年老代比较多的应用,可以提高效率。如果将此值设置为一个较大值,则年轻代对象会在Survivor区进行多次复制,这样可以增加对象再年轻代的存活时间,增加在年轻代即被回收的概论。
2、回收器选择
(1)吞吐量优先的并行收集器
① -XX:+UseParallelGC -XX:ParallelGCThreads=20
-XX:+UseParallelGC:选择垃圾收集器为并行收集器。此配置仅对年轻代有效。即上述配置下,年轻代使用并发收集,而年老代仍旧使用串行收集。
-XX:ParallelGCThreads=20:配置并行收集器的线程数,即:同时多少个线程一起进行垃圾回收。此值最好配置与处理器数目相等。
② -XX:+UseParallelOldGC
-XX:+UseParallelOldGC:配置年老代垃圾收集方式为并行收集。JDK6.0支持对年老代并行收集。
③ -XX:MaxGCPauseMillis=100
-XX:MaxGCPauseMillis=100:设置每次年轻代垃圾回收的最长时间,如果无法满足此时间,JVM会自动调整年轻代大小,以满足此值。
④ -XX:+UseAdaptiveSizePolicy
-XX:+UseAdaptiveSizePolicy:设置此选项后,并行收集器会自动选择年轻代区大小和相应的Survivor区比例,以达到目标系统规定的最低相应时间或者收集频率等,此值建议使用并行收集器时,一直打开。
(2)响应时间优先的并发收集器
① -XX:+UseConcMarkSweepGC -XX:+UseParNewGC
-XX:+UseConcMarkSweepGC:设置年老代为并发收集。测试中配置这个以后,-XX:NewRatio=4的配置失效了,原因不明。所以,此时年轻代大小最好用-Xmn设置。
-XX:+UseParNewGC:设置年轻代为并行收集。可与CMS收集同时使用。JDK5.0以上,JVM会根据系统配置自行设置,所以无需再设置此值。
② -XX:CMSFullGCsBeforeCompaction=5 -XX:+UseCMSCompactAtFullCollection
-XX:CMSFullGCsBeforeCompaction:由于并发收集器不对内存空间进行压缩、整理,所以运行一段时间以后会产生"碎片",使得运行效率降低。此值设置运行多少次GC以后对内存空间进行压缩、整理。
-XX:+UseCMSCompactAtFullCollection:打开对年老代的压缩。可能会影响性能,但是可以消除碎片
3、辅助信息
JVM提供了大量命令行参数,打印信息,供调试使用。主要有以下一些:
① -XX:+PrintGC
输出形式:
[GC 118250K->113543K(130112K), 0.0094143 secs]
[Full GC 121376K->10414K(130112K), 0.0650971 secs]
② -XX:+PrintGCDetails
输出形式:
[GC [DefNew: 8614K->781K(9088K), 0.0123035 secs] 118250K->113543K(130112K), 0.0124633 secs]
[GC [DefNew: 8614K->8614K(9088K), 0.0000665 secs][Tenured: 112761K->10414K(121024K), 0.0433488 secs] 121376K->10414K(130112K), 0.0436268 secs]
③ -XX:+PrintGCTimeStamps -XX:+PrintGC:PrintGCTimeStamps可与上面两个混合使用
输出形式:
11.851: [GC 98328K->93620K(130112K), 0.0082960 secs]
④ -XX:+PrintGCApplicationConcurrentTime:打印每次垃圾回收前,程序未中断的执行时间。可与上面混合使用
输出形式:
Application time: 0.5291524 seconds
⑤ -XX:+PrintGCApplicationStoppedTime:打印垃圾回收期间程序暂停的时间。可与上面混合使用
输出形式:
Total time for which application threads were stopped: 0.0468229 seconds
⑥ -XX:PrintHeapAtGC:打印GC前后的详细堆栈信息
输出形式:
34.702: [GC {Heap before gc invocations=7:
def new generation total 55296K, used 52568K [0x1ebd0000, 0x227d0000, 0x227d0000)
eden space 49152K, 99% used [0x1ebd0000, 0x21bce430, 0x21bd0000)
from space 6144K, 55% used [0x221d0000, 0x22527e10, 0x227d0000)
to space 6144K, 0% used [0x21bd0000, 0x21bd0000, 0x221d0000)
tenured generation total 69632K, used 2696K [0x227d0000, 0x26bd0000, 0x26bd0000)
the space 69632K, 3% used [0x227d0000, 0x22a720f8, 0x22a72200, 0x26bd0000)
compacting perm gen total 8192K, used 2898K [0x26bd0000, 0x273d0000, 0x2abd0000)
the space 8192K, 35% used [0x26bd0000, 0x26ea4ba8, 0x26ea4c00, 0x273d0000)
ro space 8192K, 66% used [0x2abd0000, 0x2b12bcc0, 0x2b12be00, 0x2b3d0000)
rw space 12288K, 46% used [0x2b3d0000, 0x2b972060, 0x2b972200, 0x2bfd0000)
34.735: [DefNew: 52568K->3433K(55296K), 0.0072126 secs] 55264K->6615K(124928K)Heap after gc invocations=8:
def new generation total 55296K, used 3433K [0x1ebd0000, 0x227d0000, 0x227d0000)
eden space 49152K, 0% used [0x1ebd0000, 0x1ebd0000, 0x21bd0000)
from space 6144K, 55% used [0x21bd0000, 0x21f2a5e8, 0x221d0000)
to space 6144K, 0% used [0x221d0000, 0x221d0000, 0x227d0000)
tenured generation total 69632K, used 3182K [0x227d0000, 0x26bd0000, 0x26bd0000)
the space 69632K, 4% used [0x227d0000, 0x22aeb958, 0x22aeba00, 0x26bd0000)
compacting perm gen total 8192K, used 2898K [0x26bd0000, 0x273d0000, 0x2abd0000)
the space 8192K, 35% used [0x26bd0000, 0x26ea4ba8, 0x26ea4c00, 0x273d0000)
ro space 8192K, 66% used [0x2abd0000, 0x2b12bcc0, 0x2b12be00, 0x2b3d0000)
rw space 12288K, 46% used [0x2b3d0000, 0x2b972060, 0x2b972200, 0x2bfd0000)
}
, 0.0757599 secs]
⑦ -Xloggc:filename:与上面几个配合使用,把相关日志信息记录到文件以便分析。
1、堆设置
① -Xms:初始堆大小
② -Xmx:大堆大小
③ -XX:NewSize=n:设置年轻代大小
④ -XX:NewRatio=n:设置年轻代和年老代的比值。如:为3,表示年轻代与年老代比值为1:3,年轻代占整个年轻代年老代和的1/4
⑤ -XX:SurvivorRatio=n:年轻代中Eden区与两个Survivor区的比值。注意Survivor区有两个。如:3,表示Eden:Survivor=3:2,一个Survivor区占整个年轻代的1/5
⑥ -XX:MaxPermSize=n:设置持久代大小
2、收集器设置
① -XX:+UseSerialGC:设置串行收集器
② -XX:+UseParallelGC:设置并行收集器
③ -XX:+UseParalledlOldGC:设置并行年老代收集器
④ -XX:+UseConcMarkSweepGC:设置并发收集器
3、垃圾回收统计信息
① -XX:+PrintGC
② -XX:+PrintGCDetails
③ -XX:+PrintGCTimeStamps
④ -Xloggc:filename
4、并行收集器设置
① -XX:ParallelGCThreads=n:设置并行收集器收集时使用的CPU数。并行收集线程数。
② -XX:MaxGCPauseMillis=n:设置并行收集大暂停时间
③ -XX:GCTimeRatio=n:设置垃圾回收时间占程序运行时间的百分比。公式为1/(1+n)
5、并发收集器设置
① -XX:+CMSIncrementalMode:设置为增量模式。适用于单CPU情况。
② -XX:ParallelGCThreads=n:设置并发收集器年轻代收集方式为并行收集时,使用的CPU数。并行收集线程数。
1、年轻代大小选择
① 响应时间优先的应用:尽可能设大,直到接近系统的最低响应时间限制(根据实际情况选择)。在此种情况下,年轻代收集发生的频率也是最小的。同时,减少到达年老代的对象。
② 吞吐量优先的应用:尽可能的设置大,可能到达Gbit的程度。因为对响应时间没有要求,垃圾收集可以并行进行,一般适合8CPU以上的应用。
2、年老代大小选择
① 响应时间优先的应用:年老代使用并发收集器,所以其大小需要小心设置,一般要考虑并发会话率和会话持续时间等一些参数。如果堆设置小了,可以会造成内存碎片、高回收频率以及应用暂停而使用传统的标记清除方式;如果堆大了,则需要较长的收集时间。最优化的方案,一般需要参考以下数据获得:
并发垃圾收集信息
持久代并发收集次数
传统GC信息
花在年轻代和年老代回收上的时间比例
减少年轻代和年老代花费的时间,一般会提高应用的效率
② 吞吐量优先的应用:一般吞吐量优先的应用都有一个很大的年轻代和一个较小的年老代。原因是,这样可以尽可能回收掉大部分短期对象,减少中期的对象,而年老代尽存放长期存活对象。
3、较小堆引起的碎片问题
因为年老代的并发收集器使用标记、清除算法,所以不会对堆进行压缩。当收集器回收时,他会把相邻的空间进行合并,这样可以分配给较大的对象。但是,当堆空间 较小时,运行一段时间以后,就会出现"碎片",如果并发收集器找不到足够的空间,那么并发收集器将会停止,然后使用传统的标记、清除方式进行回收。如果出 现"碎片",可能需要进行如下配置:
① -XX:+UseCMSCompactAtFullCollection:使用并发收集器时,开启对年老代的压缩。
② -XX:CMSFullGCsBeforeCompaction=0:上面配置开启的情况下,这里设置多少次Full GC后,对年老代进行压缩
1、分代垃圾回收详述
(1)Young(年轻代)
年轻代分三个区。一个Eden区,两个Survivor区。 大部分对象在Eden区中生成。当Eden区满时,还存活的对象将被复制到Survivor区 (两个中的一个),当这个Survivor区满时,此区的存活对象将被复制到另外一个Survivor区,当这个Survivor去也满了的时候,从第一 个Survivor区复制过来的并且此时还存活的对象,将被复制"年老区(Tenured)"。需要注意,Survivor的两个区是对称的,没先后关系,所以同一个区中可能同时存在从Eden复制过来 对象,和从前一个Survivor复制过来的对象,而复制到年老区的只有从第一个Survivor去过来的对象。而且,Survivor区总有一个是空 的。
(2)Tenured(年老代)
年老代存放从年轻代存活的对象。 一般来说年老代存放的都是生命期较长的对象。
(3)Perm(持久代)
用于存放静态文件,如今Java类、方法等。持久代对垃圾回收没有显著影响,但是有些应用可能动态生成或者调用一些class,例如Hibernate等, 在这种时候需要设置一个比较大的持久代空间来存放这些运行过程中新增的类。持久代大小通过-XX:MaxPermSize=进行设置。
2、GC类型
GC有两种类型:Scavenge GC和Full GC。
(1)Scavenge GC
一般情况下,当新对象生成,并且在Eden申请空间失败时,就好触发Scavenge GC,堆Eden区域进行GC,清除非存活对象,并且把尚且存活的对象移动到Survivor区。然后整理Survivor的两个区。
(2)Full GC
对整个堆进行整理,包括Young、Tenured和Perm。Full GC比Scavenge GC要慢,因此应该尽可能减少Full GC。有如下原因可能导致Full GC:
Tenured被写满
Perm域被写满
System.gc()被显示调用
上一次GC之后Heap的各域分配策略动态变化
3、垃圾回收器
目前的收集器主要有三种:串行收集器、并行收集器、并发收集器。
(1)串行收集器
使用单线程处理所有垃圾回收工作,因为无需多线程交互,所以效率比较高。但是,也无法使用多处理器的优势,所以此收集器适合单处理器机器。当然,此收集器也可以用在小数据量(100M左右)情况下的多处理器机器上。可以使用-XX:+UseSerialGC打开。
(2)并行收集器
① 对年轻代进行并行垃圾回收,因此可以减少垃圾回收时间。一般在多线程多处理器机器上使用。使用-XX:+UseParallelGC打开。并行收集器在J2SE5.0第六6更新上引入,在Java SE6.0中进行了增强–可以堆年老代进行并行收集。如果年老代不使用并发收集的话,是使用单线程进行垃圾回收,因此会制约扩展能力。使用-XX:+UseParallelOldGC打开。
② 使用-XX:ParallelGCThreads=设置并行垃圾回收的线程数。此值可以设置与机器处理器数量相等。
③ 此收集器可以进行如下配置:
大垃圾回收暂停:指定垃圾回收时的最长暂停时间,通过-XX:MaxGCPauseMillis=指定。为毫秒.如果指定了此值的话,堆大小和垃圾回收相关参数会进行调整以达到指定值。设定此值可能会减少应用的吞吐量。
吞吐量:吞吐量为垃圾回收时间与非垃圾回收时间的比值,通过-XX:GCTimeRatio=来设定,公式为1/(1+N)。例如,-XX:GCTimeRatio=19时,表示5%的时间用于垃圾回收。默认情况为99,即1%的时间用于垃圾回收。
(3)并发收集器
可以保证大部分工作都并发进行(应用不停止),垃圾回收只暂停很少的时间,此收集器适合对响应时间要求比较高的中、大规模应用。使用-XX:+UseConcMarkSweepGC打开。
① 并发收集器主要减少年老代的暂停时间,他在应用不停止的情况下使用独立的垃圾回收线程,跟踪可达对象。在每个年老代垃圾回收周期中,在收集初期并发收集器会 对整个应用进行简短的暂停,在收集中还会再暂停一次。第二次暂停会比第一次稍长,在此过程中多个线程同时进行垃圾回收工作。
② 并发收集器使用处理器换来短暂的停顿时间。在一个N个处理器的系统上,并发收集部分使用K/N个可用处理器进行回收,一般情况下1<=K<=N/4。
③ 在只有一个处理器的主机上使用并发收集器,设置为incremental mode模式也可获得较短的停顿时间。
④ 浮动垃圾:由于在应用运行的同时进行垃圾回收,所以有些垃圾可能在垃圾回收进行完成时产生,这样就造成了"Floating Garbage",这些垃圾需要在下次垃圾回收周期时才能回收掉。所以,并发收集器一般需要20%的预留空间用于这些浮动垃圾。
⑤ Concurrent Mode Failure:并发收集器在应用运行时进行收集,所以需要保证堆在垃圾回收的这段时间有足够的空间供程序使用,否则,垃圾回收还未完成,堆空间先满了。这种情况下将会发生"并发模式失败",此时整个应用将会暂停,进行垃圾回收。
⑥ 启动并发收集器:因为并发收集在应用运行时进行收集,所以必须保证收集完成之前有足够的内存空间供程序使用,否则会出现"Concurrent Mode Failure"。通过设置-XX:CMSInitiatingOccupancyFraction=指定还有多少剩余堆时开始执行并发收集
(4)小结
① 串行处理器:
–适用情况:数据量比较小(100M左右);单处理器下并且对响应时间无要求的应用。
–缺点:只能用于小型应用
② 并行处理器:
–适用情况:“对吞吐量有高要求”,多CPU、对应用响应时间无要求的中、大型应用。举例:后台处理、科学计算。
–缺点:应用响应时间可能较长
③ 并发处理器:
–适用情况:“对响应时间有高要求”,多CPU、对应用响应时间有较高要求的中、大型应用。举例:Web服务器/应用服务器、电信交换、集成开发环境。
4、基本回收算法
(1)引用计数(Reference Counting)
比较古老的回收算法。原理是此对象有一个引用,即增加一个计数,删除一个引用则减少一个计数。垃圾回收时,只用收集计数为0的对象。此算法最致命的是无法处理循环引用的问题。
(2)标记-清除(Mark-Sweep)
此算法执行分两阶段。第一阶段从引用根节点开始标记所有被引用的对象,第二阶段遍历整个堆,把未标记的对象清除。此算法需要暂停整个应用,同时,会产生内存碎片。
(3)复制(Copying)
此算法把内存空间划为两个相等的区域,每次只使用其中一个区域。垃圾回收时,遍历当前使用区域,把正在使用中的对象复制到另外一个区域中。次算法每次只处理 正在使用中的对象,因此复制成本比较小,同时复制过去以后还能进行相应的内存整理,不过出现"碎片"问题。当然,此算法的缺点也是很明显的,就是需要两倍 内存空间。
(4)标记-整理(Mark-Compact)
此算法结合了"标记-清除"和"复 制"两个算法的优点。也是分两阶段,第一阶段从根节点开始标记所有被引用对象,第二阶段遍历整个堆,把清除未标记对象并且把存活对象"压缩"到堆的其中一 块,按顺序排放。此算法避免了"标记-清除"的碎片问题,同时也避免了"复制"算法的空间问题。
(5)增量收集(Incremental Collecting)
实施垃圾回收算法,即:在应用进行的同时进行垃圾回收。不知道什么原因JDK5.0中的收集器没有使用这种算法的。
(6)分代(Generational Collecting)
基于对对象生命周期分析后得出的垃圾回收算法。把对象分为年青代、年老代、持久代,对不同生命周期的对象使用不同的算法(上述方式中的一个)进行回收。现在的垃圾回收器(从J2SE1.2开始)都是使用此算法的。
“Linux下Tomcat怎么开启查看GC日志和调优”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注创新互联-成都网站建设公司网站,小编将为大家输出更多高质量的实用文章!